Machine learning is a paradigm in which a model is created to do predictive analysis based on the training it has received on the existing data. There are broadly two different types in which the training of a model can take place:
- Distributed manner (where the data for training of the model takes place across nodes)
- Centralized manner (Training takes place in bulk and at once)
Both learning approaches are different from each other in goals and architecture.
Centralized Learning
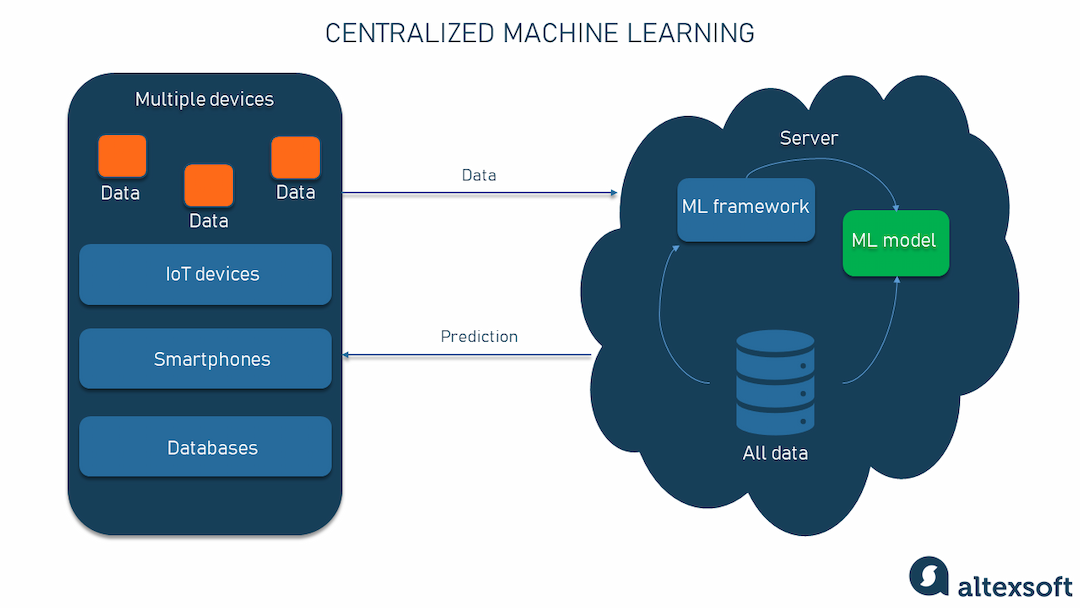
Centralized learning is a traditional approach where all data and computations are concentrated in a single location, typically a robust server or data center. This strategy excels when data aggregation is feasible and centralized resources can be fully utilized for optimal performance.
Architectural Framework:
Data is meticulously collected, processed, and housed within a central repository or server. Model training and inference occur exclusively on the central server, leveraging its potent processing capabilities. This method often employs powerful hardware, such as GPUs or TPUs, to handle computationally intensive tasks.
Core Objectives:
Maximize computational efficiency by harnessing centralized resources. Minimize delays in model training and inference by having a single location for all operations. Streamline data management and model deployment through centralized operations.
Structure Breakdown:
Data is meticulously collected from various sources and aggregated into a central storage system. A single machine learning model is trained on the entire dataset residing on the central server. The trained model is deployed on the central server to make predictions on new data.
An Example of Centralized Learning using TensorFlow
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Load dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Define a simple model
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dense(10, activation='softmax')
])
# Compile and train the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train.reshape(-1, 784), y_train, epochs=5)
# Evaluate the model
model.evaluate(x_test.reshape(-1, 784), y_test)
Distributed Learning
Distributed learning diverges from the centralized paradigm by distributing data and computations across numerous devices or nodes, enabling parallel processing and enhanced scalability. This approach is advantageous in scenarios where data is inherently distributed, such as data generated by IoT devices or mobile applications.
Architectural Framework:
Data is divided and stored across multiple devices or nodes. Model training and inference are distributed among various nodes, each handling a subset of the data. Nodes communicate and synchronize with each other to exchange model updates and ensure consistency.
Core Objectives:
Scale processing capabilities efficiently by distributing the workload across multiple devices. Enhance data privacy by keeping sensitive data on local devices, minimizing the need for transfer to a central server. Improve system resilience by decentralizing computation, reducing the risk associated with a single point of failure.
Structure Breakdown:
Data is divided into subsets, with each subset stored on a distinct node or device. Each node independently trains a local model on its designated data subset. Periodically, the local models or their gradients are sent to a central server or coordinator node to update the global model. Nodes synchronize their models to maintain consistency and improve overall performance.
An Example of Federated Learning Implementation:
- Federated Learning: Mobile devices train local models on user data and send updates to a central server for aggregation, commonly used by companies like Google for improving personalized services while safeguarding user privacy.
- Distributed Training Frameworks: Utilizing tools like Apache Spark or TensorFlow Distributed for scalable model training.
import tensorflow as tf
import tensorflow_federated as tff
# Define a simple model
def create_keras_model():
return tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='softmax', input_shape=(784,))
])
def model_fn():
return tff.learning.from_keras_model(
create_keras_model(),
input_spec=train_data.element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
# Load federated dataset (replace with your data loading logic)
federated_train_data = [get_client_data(client_id) for client_id in client_ids]
# Create a federated averaging process
iterative_process = tff.learning.build_federated_averaging_process(model_fn)
# Initialize the model
state = iterative_process.initialize()
# Train the model in a federated manner
for round_num in range(1, num_rounds+1):
state, metrics = iterative_process.next(state, federated_train_data)
print(f'Round {round_num}, Metrics={metrics}')
How Federated learning is different from distributed learning?
Federated learning is a specific type of distributed learning where the training of a model is distributed across many devices (often edge devices like smartphones), with each device using its local data. However, there are differences between the both in use cases.
Data Distribution
While both distributed learning and federated learning involve training models across multiple machines, distributed learning is characterized by a centralized data storage and processing approach within a high-performance environment, whereas federated learning emphasizes decentralized data storage and local training on diverse, distributed devices to enhance privacy.
Architectural Differences
- Distributed learning: A central server often coordinates the training process, distributing tasks to worker nodes and aggregating their results. High communication bandwidth is typically required between the central server and the worker nodes.
- Federated learning: A central server coordinates the training process but only receives model updates (gradients or weights) rather than raw data. Lower communication bandwidth is required since only model updates are communicated, not raw data.
Privacy
- Distributed learning: Data privacy is not inherently emphasized, as data is centralized and can be accessed by the central server.
- Federated learning: Privacy is a primary concern. Raw data never leaves the local devices, which helps protect user privacy.
Use Cases
- Distributed learning: Suitable for scenarios where computational power is more important than data privacy, such as large-scale data analysis and scientific computing.
- Federated learning: Ideal for applications where data privacy is crucial, such as medical data analysis, personalized recommendations, and mobile applications.